验证码识别是一个有意思的项目,很多时候多用于非法抓取,批量处理之类的,给网站运营者造成了一定的损失,这里我们研究验证码识别单纯研究图像识别技术。
文章主要利用python代码演示,就算你不懂,相信python简洁的自然语言话的语法也能让你理解,图像处理主要用PIL库
先来看看一个验证码,来自http://www.ruanko.com/validateImage.jsp

利用一些图像处理或者图像查看软件来看看,验证码尺寸为60×20每个字母的尺寸为13×9而且验证码位置相对固定,这就是一个很适合我们初学者学习的一个例子,对于字体的分割相对容易一点
我们批量下载50个验证码来取字库,python提供方便的下载功能,脚本如下
import urllib
for i in range(50):
url = 'http://www.ruanko.com/validateImage.jsp'
print "download", i
file("./code/%04d.jpg" % i, "wb").write(urllib.urlopen(url).read())
这样你就可以在code目录找到这50个验证码了
然后适当处理图片将其二值化,这里可以利用我前面一篇文章里面的算法(python图像处理之二值去噪)代码不罗列了,处理之后会得到这样的效果

然后分割字符,这里利用PIL中图像分割的一块
import urllib
for i in range(50):
url = 'http://www.ruanko.com/validateImage.jsp'
print "download", i
file("./code/%04d.jpg" % i, "wb").write(urllib.urlopen(url).read())
50个验证码就被分别分割成四个字母了,如图

手工从其中选出比较完整的一套字模,如图

这样我们一个字库就完成了,在来谈谈匹配算法,相似度匹配,我们马上想法哦了异或算法,即把不同的去出来,然后进行一个计数,不同的点越少,相似读越高,例如这样一个图
进行异或运算,得到
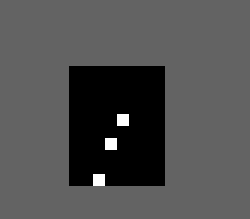
在PIL中实现如下
for yi in range(13):
for xi in range(9):
if mod[1].getpixel((xi, yi)) != target.getpixel((xi, yi)):
diffs += 1
diffs表示不同的点的个数,然后取diff最小的那个图片的值作为识别的值
总结一下前面的步骤,我们来看看完整代码
#!/usr/bin/env python
# −*− coding: UTF−8 −*−
import os, Image
def binary(f):
img = Image.open(f)
#img = img.convert('1')
pixdata = img.load()
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][0] < 90:
pixdata[x, y] = (0, 0, 0, 255)
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][1] < 136:
pixdata[x, y] = (0, 0, 0, 255)
for y in xrange(img.size[1]):
for x in xrange(img.size[0]):
if pixdata[x, y][2] > 0:
pixdata[x, y] = (255, 255, 255, 255)
return img
def division(img):
font=[]
for i in range(4):
x=7+i*13
y=3
font.append(img.crop((x,y,x+9,y+13)))
return font
def recognize(img):
fontMods = []
for i in range(10):
fontMods.append((str(i), Image.open("./num/%d.bmp" % i)))
result=""
font=division(img)
for i in font:
target=i
points = []
for mod in fontMods:
diffs = 0
for yi in range(13):
for xi in range(9):
if mod[1].getpixel((xi, yi)) != target.getpixel((xi, yi)):
diffs += 1
points.append((diffs, mod[0]))
points.sort()
result += points[0][1]
return result
if __name__ == '__main__':
codedir="./code/"
for imgfile in os.listdir(codedir):
if imgfile.endswith(".jpg"):
dir="./result/"
img=binary(codedir+imgfile)
num=recognize(img)
dir += (num+".png")
print "save to", dir
img.save(dir)
我把字库放在了num目录里,然后会识别出来存放在result目录结果如下

http://blog.feshine.net/technology/1163.html